
Crawling conversation sites for language modeling data
How to use Scrapy to obtain vast amounts of data for language modeling
Creating web spiders with Scrapy
In the past, a common way to obtain language model training data from the web has involved generating Google queries using in-domain data. When trying to collect Finnish conversations, I found this method very inefficient. It might be that something has changed in how Google handles queries, or Google finds less conversational Finnish data, or that my set of in-domain n-grams was too small. In any case, I found crawling large conversation sites using Python and Scrapy to be way more efficient. Using Scrapy can initially seem like a lot of work, but usually the same spider can be adapted to different sites with only small changes. A single conversation site contains millions or billions of words of conversations.
Creating a new project has been made easy. After installing Scrapy, create the directory structure using:
scrapy startproject mybot
Before writing the actual spider, let’s look at a few details that need to be
filled in the files that the command created. mybot/items.py defines a class
for storing a single data item, in this case a message extracted from a
conversation site. I also extract a unique ID for each message. It can be a
unique URL or some attribute in the HTML code that the site uses. The file looks
like this:
from scrapy.item import Item, Field
class MessageItem(Item):
id = Field()
text = Field()
mybot/pipelines.py defines components of a pipeline that is used to process
all extracted data items. Pipeline components are classes that implement
process_item() method. The method is called on every extracted item by the
Scrapy framework. I have used two components—one that filters duplicate items,
and one that writes the item to disk:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.seen_ids = set()
def process_item(self, item, spider):
if item['id'] in self.seen_ids:
raise DropItem("Duplicate item: " + str(item['id']))
else:
self.seen_ids.add(item['id'])
return item
class WriterPipeline(object):
def __init__(self):
self.output_file = open('messages.txt', 'a')
def process_item(self, item, spider):
self.output_file.write('###### ')
self.output_file.write(str(item['id']))
self.output_file.write('\n')
self.output_file.write(item['text'])
self.output_file.write('\n')
return item
The spider can be configured in mybot/settings.py, which also defines what
pipeline components will be used to process the extracted items:
BOT_NAME = 'mybot'
DOWNLOAD_DELAY = 0.5
SPIDER_MODULES = ['mybot.spiders']
NEWSPIDER_MODULE = 'mybot.spiders'
ITEM_PIPELINES = [
'mybot.pipelines.DuplicatesPipeline',
'mybot.pipelines.WriterPipeline'
]
DOWNLOAD_DELAY specifies a time in seconds to wait before downloading
consecutive pages from the same site. This is important because downloading too
fast may cause your bot to overload the web server, prevent the site from being
used, or make the site block requests from your bot.
Crawling static web pages
The actual spider class that extracts the data items from HTML pages you’ll have
to implement in mybot/spiders/mysite_spider.py. Crawling a site that uses
static HTML is straightforward. Every site structure is a bit different, though,
so you’ll have to customize the spider for each site. You need to specify the
rules for following links to different conversations, and implement a function
that parses the messages from a conversation page. This is how the file usually
starts:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from mybot.items import MessageItem
class MysiteSpider(CrawlSpider):
name = "mysite-spider"
allowed_domains = ["mysite.com"]
start_urls = ["http://mysite.com/viewforum.php"]
extractor = SgmlLinkExtractor(allow=('view(topic|forum)\.php'))
rules = (
Rule(extractor, callback='parse_item', follow=True),
)
def parse_item(self, response):
# Parse messages from the response.
A CrawlSpider automates the process of following links on the loaded web
pages. start_urls defines one or more top-level URLs, where to start crawling.
allowed_domains limits the spider to links that point to this domain name. You
probably want to stay inside the same domain and not to follow external links.
extractor is an object that extracts the links that the spider should follow
from a web page. You should provide a regular expression in the allow
parameter that matches only those pages that contain conversations or links to
conversation threads.
Implementation of the parse_item function depends on the HTML structure of the
site. It should iterate through all the messages in the HTML code, and yield a
new item on each message. Iterating through the messages is facilitated by
XPath selectors, a
mechanism for identifying HTML elements. At its simplest, the function could
look something like this:
def parse_item(self, response):
selector = Selector(response)
for message in selector.xpath('//div[@class="message"]'):
ids = message.xpath('@id').extract()
if len(ids) != 1:
continue
id = ids[0]
text = '\n'.join(message.xpath('text()').extract())
if not text:
continue
item = MessageItem()
item['id'] = id
item['text'] = text
yield item
The XPath //div[@class="message"] is used to select all <div> elements from
the document with class attribute set to “message”. Proper instructions on using
XPath selectors are out of the scope of this post, but there are a few things
that can be noted from the code. The select() method always returns a list,
because there can be multiple elements that match the search. A useful feature
is that the returned objects are selectors themselves that can be used to select
nested objects. Without the leading //, an XPath selects child elements. In
this case the <div> selector is used to select its id attribute and the text
inside the element. extract() method is used to convert a selector to a text
string.
So how do you find out how the elements that you want to select can be identified? You could of course look at the HTML source code. An easier way, and the only way with dynamic web pages, is to use a browser that supports inspecting the HTML document. For example, in Google Chrome you can right-click an element and select “Inspect”. A panel showing the document structure appears below the web page. Inspecting a phpBB message looks something like this:
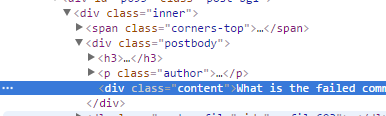
In the above example, text inside the content div could be selected for example
with the XPath //div[@class="postbody"]/div[@class="content"]/text(). An easy
way to test it is to load the page in Scrapy shell, e.g:
scrapy shell http://mysite.com/viewtopic.php?f=123&t=456
A Python interpreter opens with response variable already set. Now you can
select the text elements:
response.xpath('//div[@class="postbody"]/div[@class="content"]/text()')
Notice that this returns a list of selectors. Use the extract() method to
get the text data.
Crawling dynamic web pages
It gets a bit more involved if the site creates pages dynamically, on the client side. Then the client needs to load the page and execute any JavaScript code, which is clearly too much functionality to be implemented in Scrapy. Selenium WebDriver library enables a script to drive a web browser, primarily intended for testing web applications. It can be used to load a web page in a browser, and read the generated HTML document. The document can then be parsed using Scrapy.
Now that Scrapy is not able to read the links from the HTML pages, a
CrawlSpider cannot be used to automatically crawl through the site. The
solution is to derive from the simpler base class Spider, and manually extract
and follow links. The base class reads just the start page and calls parse()
method. The response that is passed to parse() is just the static page, so the
method needs to reload the URL using Selenium. This is how I have structured the
class:
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapy.http import Request, TextResponse
from selenium import webdriver
from mybot.items import MessageItem
import time
from collections import deque
class MysiteSpider(Spider):
name = "mysite-spider"
start_urls = ["http://mysite.com/forum"]
def __init__(self):
Spider.__init__(self)
self.verificationErrors = []
# You can use a specific Firefox profile by
# creating a selenium.webdriver.FirefoxProfile
# and passing it to the webdriver constructor.
self.selenium = webdriver.Firefox()
self.seen_urls = set()
self.url_queue = deque()
def __del__(self):
self.selenium.quit()
print(self.verificationErrors)
def parse(self, response):
# response is the start page as seen by Scrapy.
# Call parse_url() to reload it using Selenium.
def parse_url(self, page_url):
# Load a URL using Selenium.
seen_urls is maintained to avoid processing the same URL multiple times. URLs
to be visited are kept in url_queue. parse() reads just the URL from the
response, and calls parse_url() to load the document in a browser and process
it. It will also call parse_url() for any URLs that are added to url_queue
while processing a page.
parse_url() may have to wait a few seconds for the document to load. Then it
creates a new response and XPath selector for parsing the document. It has to
identify the links that should be followed, either using an XPath, or based on
the URL. If the URL is found in seen_urls, it has been queued already. Links
to be processed can be added to url_queue. It’s also possible to yield
requests that Scrapy will process using a different handler.
def parse(self, response):
requests = [x for x in self.parse_url(response.url)]
while self.url_queue:
url = self.url_queue.popleft()
requests.extend([x for x in self.parse_url(url)])
for request in requests:
yield request
def parse_url(self, page_url):
self.selenium.get(page_url)
if self.selenium:
time.sleep(3)
page_source = self.selenium.page_source
response = TextResponse(url=page_url,
body=page_source,
encoding='utf-8')
selector = Selector(response)
for link in selector.xpath('//a'):
urls = link.select('@href').extract()
if len(urls) != 1:
continue
url = urls[0]
if url in self.seen_urls:
continue
self.seen_urls.add(url)
if is_forum_url(url):
self.url_queue.append(url)
# It's possible to yield a request that will
# be handled by a custom callback function.
if is_special_url(url):
yield Request(url, callback=self.parse_special)
Comments